Let’s Go¶
イントロダクション¶
このドキュメントはGoプログラミング言語の基本を紹介するチュートリアルです。CやC++に親しんだプログラマを対象にしています。このドキュメントは包括的なドキュメントではありません。そのような目的に一番近いのは言語仕様のドキュメントになります。このチュートリアルを読むと、言語をどのように使うのかという詳細を掘り下げるために、次にEffective Goが読みたくなるでしょう。また、Goに関する3日コースのスライドも入手することができます。 1日目 2日目 3日目
このプレゼンテーションの中のシンプルなサンプルプログラムを通して、この言語のキーとなる機能について、説明していきます。すべてのプログラムは自分で書いてみても動作しますし、 /doc/progs/ の中に置いてあります。
プログラムのコードはオリジナルのファイルの行番号付きで表示しています。見やすさのために、空行はブランクのまま残してあります。
Hello, World¶
それでは、いつもの入門コードから始めます:
05 package main
07 import fmt "fmt" // フォーマット付き入出力を実装したパッケージ
09 func main() {
10 fmt.Printf("Hello, world; or Καλημ?ρα κ?σμε; or こんにちは 世界\n");
11 }
すべてのGoのソースファイルは、そのファイルが属しているパッケージを宣言するために、package文の宣言を行います。また、他のパッケージに含まれる機能を利用するために、他のパッケージをインポートすることもあります。このプログラムでは、パッケージ名付きで先頭の大文字化はされているという違いはありますが、C/C++プログラマにはおなじみの、古くからの友人である、fmt.Printf()を使用するために、fmtパッケージをインポートしています。
funcキーワードを使用することで、関数を定義することが出来ます。mainパッケージのmain関数は、いくつかの初期化の後に最初に呼ばれるプログラムの入り口になります。
文字列定数はUTF-8でエンコードされていて、ユニコード文字を含むことができます。実際に仕様上でも、GoのソースファイルはUTF-8でエンコードされると定義されています。
コメントの書き方は、C++で行われている慣習と同じです。
/* ... */
// ...
後の方の説明では、画面表示に関しても、もっと詳しく説明していきます。
セミコロン¶
プログラムにセミコロンが無いことに気付いたでしょうか。Go言語のコードでは、通常セミコロンが見られるのはループの節を分けるなどの場面だけです。1行ごとに行末に書く必要はありません。
実際、まさにCやJavaといったお堅い言語ではセミコロンを使いますが、ステートメントの終わりの様に見えるすべての行の末尾に自動的にセミコロンが挿入されます。あなた自身がタイプする必要はありません。
詳細については言語仕様を参照してもらうとして、実際には「行末にセミコロンを置く必要は無い」というとだけを覚えておけば充分でしょう(1行に複数ステートメントを記述したい場合は、セミコロンを置くことも可能です)。蛇足ですが、閉じ中括弧(“}”)の直前のセミコロンは省略しても構いません。
このアプローチはセミコロン無しのコードになり、見た目がすっきりします。意外かもしれませんが、ifステートメントなどでその構成体の中括弧(“{”)を同じ行に記述することは重要です。そうしなければ、コンパイルできないか不正な結果となる状況になります。この言語は、中括弧のスタイルを強要するところがあります。
コンパイル¶
Goはコンパイル型言語です。現状のところコンパイラが2つあります。GccgoはGCCバックエンドを利用するコンパイラです。またアーキテクチャーごとに異なる(そしておかしな)名前のコンパイラーが一式あります。64-bit x86用の6g、32-bit x86用の8などです。これらはとても高速ですが、gccgoより非効率なコードを生成します。執筆時点(2009後半)では、gccgoも追い上げていますが、より堅牢なランタイムシステムを持ちます。
プログラムをコンパイルして走らせる方法を紹介します。6gだと
$ 6g helloworld.go # コンパイル; オブジェクトはhelloworld.6となる
$ 6l helloworld.6 # リンク; 出力は6.outとなる
$ 6.out
Hello, world; or Καλημ?ρα κ?σμε; or こんにちは 世界
$
gccgoだともう少し従来のやりかたに似ています。
$ gccgo helloworld.go
$ a.out
Hello, world; or Καλημ?ρα κ?σμε; or こんにちは 世界
$
Echo¶
次は、Unixコマンドのecho(1)と同じ動作をするサンプルです。
05 package main
07 import (
08 "os";
09 "flag"; // command line option parser
10 )
12 var omitNewline = flag.Bool("n", false, "don't print final newline")
14 const (
15 Space = " ";
16 Newline = "\n";
17 )
19 func main() {
20 flag.Parse(); // Scans the arg list and sets up flags
21 var s string = "";
22 for i := 0; i < flag.NArg(); i++ {
23 if i > 0 {
24 s += Space
25 }
26 s += flag.Arg(i)
27 }
28 if !*omitNewline {
29 s += Newline
30 }
31 os.Stdout.WriteString(s);
32 }
このプログラムは小さいですが、多くの新しいことが出てきます。 最後の例で、”func”を確認しました。 今回は、”var”, “const”, “type(まだ使いませんが)”, パッケージ利用前に宣言する”import”を使用します。 注意点として、7-10, 14-17行目のように、セミコロンで区切りことにより、同じ種類の宣言を並べて記述することができます。 しかし、必ずしもそう記述する必要はありません。 次のコードでも良いと言ったのですが、
const Space = " "
const Newline = "\n"
セミコロンはここで必要ではありません。 事実上、セミコロンはどんなトップレベル宣言の後にも不要です。 “()”を利用し複数宣言する場合に区切り文字として必要です。
C、C++、またはJavaと同じようにセミコロンを使用できますが、多くの場合、れらを省くことができます。セパレータステートメントの処理の前に処理自体を切り離すため、ブロックの最後にセミコロンは必要ではありません (まだOKです)。Cのように、ブレス後につけることは任意です。
echoサンプルのソースコードを見てみましょう。プログラム中にセミコロンが必要な箇所は、8,15,21行目にあり、22行目は、forループの要素間の記述のため必要です。9,16,26,31行目のものは任意ですが、リストの最後、ステートメントの最後が簡単にわかるようにするために付けています。
このプログラムは、Stdout変数にアクセスするために、”os”をインポートしています。, of type *os.File. “import”句は、パッケージを利用する場合に明示的に宣言します。 “hello,world”のサンプルでは、見つけられたファイル(“fmt”)からインポートされたパッケージのメンバーにアクセスするための識別子を(fmt)と命名しています。インポート対象は、カレントディレクトリか、標準の位置にある必要があります。 もっとも、今回のサンプルでは、インポート時に明白な名前を落としました。 識別子を指定しない場合は、ファイル名を利用してインポートします。 “hello, world”のサンプルでは、明示して、”fmt”パッケージをインポートしています。
必要であれば、パッケージ名の競合を解決するために名前を指定することができます。
os.Stdout の WriteString メソッドを利用することで、文字列を出力することができます。
12行目では、flagパッケージをインポートし、”-n”が実行時に与えられたかを保持するグローバル変数を作成しています。 omitNewline変数は、*bool型で、boolへのポインタです。
mainメソッドの中では、20行目に実行時引数を分析して、次に、出力用のローカル変数を作成します。
変数の宣言は以下のようになります。
var s string = "";
var キーワードに続き、変数名、変数の型、=に続き初期化する値を記述します。
Go は簡潔になろうとしています、変数の宣言ではそれができました。string型は、文字列定数なので、コンパイラに通知する必要がありません。次のように記述することもできます。
var s = "";
変数は以下のように、もっと短く記述することもできます。
s := "";
:=オペレータは、初期化時にGoで大いに使用されます。 次の行の節でも1つでてきます。
22 for i := 0; i < flag.NArg(); i++ {
flagパッケージは、実行時引数を解析し、オプション引数以外をわかりやすく繰り返し取得できるリストにしてくれます。
Go の for文の書式は、Cのものと多く異なっています。 最初に、ループ構造です。 while文、do文がありません。 次に、節を示す括弧がありません。”()”、しかし 中括弧”{}”によるブレスが必要です。 これらは、if文、switch文にも当てはまります。 後述する例で示します。
プログラム中では、出力用変数 s に対して、スペースを区切り文字として追加しています。 このとき (+=)を使っています。 ループが完了後に、コマンドライン引数で、”-n”が指定されていなければ、改行を追加しています。最後に、結果を標準出力に出力しています。
mainメソッドの戻り値が無い場合は、 niladicメソッドとなります。 戻り値がなくとも、その様に定義されます。 mainメソッドが終了すれば、”success”を意味します。 もし、エラー終了としたい場合は、以下の式を呼び出してください。
os.Exit(1)
osパッケージはプログラムを開始するための基礎部分を含んでいます。 例えば、os.Argsは、コマンドライン引数へアクセスするために、flagパッケージを使っています。
型¶
Go には多くの int や float のような型がありますが、 これらの値のサイズは実行するマシンで ‘’適切’’ なサイズになります。このため、 サイズが明示的な型として int8, float64 などの型や、 負数のない整数型といった uint, uint32 なども定義されています。 型名が異なる型は、明確に別の型としてあつかわれるので、 int と int32 はどちらもサイズが32ビットですが、異なる型となります。 他に、 uint8 の別名である byte という型があり、 これは文字列の要素のための型です。
string 型という組み込み型もあります。文字列は 変更不可能な値 で、 単なる byte 型の配列ではありません。一度、文字列型の値を作ると、 この値を変更する事は出来ず、文字列を変更は出来ますが実質的には、別の 文字列型の値が割り当てられることになります。以下は strings.go の ソースコードの一部です。
11 s := "hello";
12 if s[1] != 'e' { os.Exit(1) }
13 s = "good bye";
14 var p *string = &s;
15 *p = "ciao";
ところで、以下は不正なコード例です。これは string の値を書き換えようと しているからです。
s[0] = 'x';
(*p)[1] = 'y';
C++ の言い方で言えば、 Go の文字列は const strings と言えます。また、 これを参照するポインタも同じように const strings への参照と言えます。
そう、ポインタがあります。でも Go のポインタは少し使いやすく簡単になって います。見ていきましょう。
配列は以下のように宣言されます。
var arrayOfInt [10]int;
配列は文字列のような、値の集まりですが、これらは変更可能です。 arrayOfInt と C との違いは、 int へのポインタとして使う事が出来るところです。 Go では、配列は値の集まりで、配列へのポインタとして使えるという意味になります。
この配列のサイズは型の一部なので、変数のスライスを宣言したり、 to which one can assign a pointer to any array with the same element type – もっと一般的な利用例として – スライスは a[low : high] と言う風に表現し、これによって元の配列の low から high-1 の要素を持つ部分配列となります。スライスはほとんど配列のように見えますが、明確なサイズ情報を持たず ([] vs. [10]) 、they reference a segment of an underlying, often anonymous, regular array. 複数のスライスは、元の配列が同じものであればデータを共有することができますが、異なる複数の配列がデータを共有することは決してありません。
スライスは Go のプログラムでは正規の配列よりもずっと一般的で、フレキシブルで、参照の記法があり、効率的です。スライスに欠けているのは記憶域における正確なデータ構成の制御で、もしあなたが100個の配列要素を構造体の中に格納しようとするなら、正規の配列を使わなければいけません。
配列を関数に渡すとき、大体の場合、スライスを受け取るように宣言したいと思います。こうすれば関数を呼び出すとき、関数は配列のアドレスを受け取って、 Go はスライスの参照を作って(効率的に)渡すでしょう。
スライスの使い方として以下のように関数を書けます(sum.goより)。
09 func sum(a []int) int { // intを返す
10 s := 0;
11 for i := 0; i < len(a); i++ {
12 s += a[i]
13 }
14 return s
15 }
そして呼び出し側は以下のようになります。
19 s := sum(&[3]int{1,2,3}); // 配列のスライスをsumに渡す
sum() の返値の型 (int) がパラメータリストの後ろに定義されていることに注意してください。 [3]int{1,2,3} という表現 – 型の後ろにブレースに囲まれた表現がある – は値のコンストラクタで、この例では3つの int 値を持つ配列を作っています。 & を前に置くことで、値のインスタンスの唯一のアドレスを取得することが出来ます。 sum() 関数にポインタを渡すことで (暗黙的に) 配列をスライスに変形させています。
もし正規の配列を作るときにコンパイラに要素の数を数えさせるようにするには、 ... を配列のサイズとして使います。
s := sum(&[...]int{1,2,3});
慣習として、もし記憶域でのデータ構成を気にしないのであれば、スライスをそのまま – 空のブラケットに & 無しで – 渡せば良いことになります。
s := sum([]int{1,2,3});
マップを使う場合は、以下のように初期化出来ます。
m := map[string]int{"one":1 , "two":2}
組み込み関数 len() は要素数を返しますが、最初にお見せした sum() 関数の中で使っています。これは文字列、配列、スライス、マップ、そしてチャンネルでも動作します。
An Interlude about Allocation¶
Goでは、ほとんどの型は値です。 int や struct や array は代入時にオブジェクトの内容をコピーします。新しい変数を割り当てるためには new() を使います。 new() は割り当てた記憶域へのポインタを返します。
type T struct { a, b int }
var t \*T = new(T);
またはより慣用的には次のようになります。
t := new(T);
マップやスライスやチャンネル(下記参照)のような型は参照セマンティックです。スライスやマップの内容を変更すると、同じデータを参照している他の変数でも変更が反映されます。これらの型を生成するには組み込み関数 make() を使います。
m := make(map[string]int);
この文ではエントリーを格納する新しいマップを初期化しています。マップを宣言するためには次のようにします。
var m map[string]int;
ここではなにも保持していない nil 参照を生成しています。マップを使うためには、まずはじめに make() を使って参照を初期化するか既存のマップを代入する必要があります。
make(T) は T の型を返すのに対して new(T) は *T の型を返すことに注意してください。(間違えて) new() で参照オブジェクトの割り当てを行うとnil参照へのポインタが返されてしまいます。これは未初期化の変数を宣言してそのアドレスを受け取ることと同等です。
定数¶
Goでは多くの整数型サイズの変数がありますが、整数型定数はありません。 0LL や 0x0UL のような定数はありません。 その代わり、単精度変数に割り当てようとして桁溢れした場合には 整数型定数は多精度変数として評価されます。
const hardEight = (1 << 100) >> 97 // これは正しい
言語仕様には変換に関する記述がありますが、ここではいくつか実例を示します。
var a uint64 = 0 // uint64型 値0の変数
a := uint64(0) // "conversion"に相当する使い方です
i := 0x1234 // iのデフォルト型はintとなります
var j int = 1e6 // 正しい - 整数型では1000000に置き換えられます
x := 1.5 // 浮動小数点型
i3div2 := 3/2 // 整数型の除算 - 結果は1となります
f3div2 := 3./2. // 浮動小数点型の除算 - 結果は1.5となります
型変換は、 整数配列 の別シンボルへの変換や他のサイズとの変換のような簡単なケースや、 整数配列 と 浮動小数点配列 の変換、 そしてその他のいくつかの簡単なケースでのみ動作します。 Goでは具体的なサイズと型を割り当てられていない変数はどんな型でも自動で変換はされません。
I/O Package¶
次に、ファイルのオープン、クローズ、読み込み、書き込みを行うインターフェイスを含んだシンプルなパッケージを見てみましょう。以下はfile.goの書き出しの部分です。
05 package file
07 import (
08 "os";
09 "syscall";
10 )
12 type File struct {
13 fd int; // ファイル記述子番号
14 name string; // ファイルを開く時の名前
15 }
最初の数行でパッケージ名-ファイル名を宣言してから、2つのパッケージをインポートしています。osパッケージは様々なオペレーティングシステム間の違いを吸収して、ファイルなどを一貫して利用できる様にします。ここで、エラー制御機構を使用し、ファイルI/Oの基本を実装します。
もう一方のパッケージは、オペレーティングシステムを呼び出す、低レベルなsyscallパッケージです。
次は、型の定義です。Fileというデータ構造を定義している様に、typeキーワードは型の宣言をする時に使用します。趣向を凝らして、このFile構造体はファイル記述子とその参照先であるファイル名を含んでいます。
File型は、大文字から始まるため、型はパッケージの外部、つまり、パッケージを利用する側から参照する事が出来ます。Go言語の情報可視性に関するルールは簡単です。もし(トップレベルの型、関数、メソッド、定数、変数、もしくは構造体のフィールド、メソッドの)名前が大文字で書かれている場合、パッケージを利用する側から参照する事が出来ます。 つまり、大文字にしなければ、それらが宣言されたパッケージ内でのみ参照できません。このルールはコンパイラによって行われます。Go言語では、外部から参照出来る状態であることを”エクスポートされた(exported)”と呼びます。
File型の場合、そのフィールドが全て小文字のためパッケージの利用側から参照出来ませんが、大文字で始まるエクスポートされたメソッドを後程追加します。
まず、これはFile型のオブジェクトをを生成するファクトリです。
17 func newFile(fd int, name string) \*File {
18 if fd < 0 {
19 return nil
20 }
21 return &File{fd, name}
22 }
この関数の戻り値は、新しく作られたFile構造体のポインタで、フィールドにファイル記述子とファイル名が格納されています。このコードはマップや配列を作成する際の書き方に似ています。これはGo言語の”複合リテラルCcomposite literal”という概念で、これを使ってオブジェクトに新しいヒープ領域を割り当てます。次のような書き方もできます。
n := new(File);
n.fd = fd;
n.name = name;
return n
Fileのような単純構造でなければ、21行目で行っているように複合リテラルでアドレスを返す方が、より簡単です。
エクスポートされた*File型の変数を作成するためには、ファクトリ関数を使用することができます。
24 var (
25 Stdin = newFile(0, "/dev/stdin");
26 Stdout = newFile(1, "/dev/stdout");
27 Stderr = newFile(2, "/dev/stderr");
28 )
newFile関数は内部にあるため、エキスポートされません。エクスポートするべきものはOpen関数です。
30 func Open(name string, mode int, perm int) (file \*File, err os.Error) {
31 r, e := syscall.Open(name, mode, perm);
32 if e != 0 {
33 err = os.Errno(e);
34 }
35 return newFile(r, name), err
36 }
この数行には、新しく出てきた要素が多くあります。まず、Open関数は、Fileやエラー(エラーについては後述)といった複数の値を返します。複数の値を返す場合には、カッコで囲んだリストで記述します。構文的には第2引数のリストのように見えます。
syscall.Open関数も、31行目の様に複数の変数に代入できるような、複数の返却値を持ちます。rとeが2つのint型の値(syscallパッケージを参照する必要があります)を保持するということです。
最後は、35行目で新しいファイルへのポインタとエラーの2つの値を返している点です。もし、syscall.Openが失敗した場合に、ファイル記述子であるrは負の値となり、NewFile関数はnilを返します。
これらのエラーについては、OSライブラリは包括的な概念が含まれています。 ここで示す様に、関数間でエラー情報を受け渡す際に、共通のエラー機能を仕様するのは、Goコード内で一貫したエラー処理を行うための良い方法です。Openメソッドでは、Unixの整数で表されるerrno値を、os.Error型を使用し、os.Errno型に変換します。
これで、Fileを作成することが出来るようになったので、それらのメソッドを書くことができます。型のメソッドを記述するためには、定義する関数名の前のカッコ内に、レシーバを型を明示して記述します。以下に記述する*Fileの各メソッドでは、それぞれfileレシーバ変数を宣言しています。
38 func (file \*File) Close() os.Error {
39 if file == nil {
40 return os.EINVAL
41 }
42 e := syscall.Close(file.fd);
43 file.fd = -1; // so it can't be closed again
44 if e != 0 {
45 return os.Errno(e);
46 }
47 return nil
48 }
50 func (file \*File) Read(b []byte) (ret int, err os.Error) {
51 if file == nil {
52 return -1, os.EINVAL
53 }
54 r, e := syscall.Read(file.fd, b);
55 if e != 0 {
56 err = os.Errno(e);
57 }
58 return int(r), err
59 }
61 func (file \*File) Write(b []byte) (ret int, err os.Error) {
62 if file == nil {
63 return -1, os.EINVAL
64 }
65 r, e := syscall.Write(file.fd, b);
66 if e != 0 {
67 err = os.Errno(e);
68 }
69 return int(r), err
70 }
72 func (file \*File) String() string {
73 return file.name
74 }
レシーバ変数は明示的に定義する必要があり、構造体のメンバにアクセスするためには、レシーバ変数を使用する必要があります。メソッドは構造体内では宣言しません。構造体の宣言内で定義するのはデータメンバのみです。実際はメソッドは構造体だけではなく、整数や配列などほぼすべての型に作成することができます。配列を使った例は後で記述します。
Stringメソッドは、後ほど説明する文字出力変換に利用されるメソッドです。
これらのメソッドはUnixのエラーコードEINVAL(これをos.Errorに変換したもの)を返すためパブリックな変数であるos.EINVALを使用しています。osライブラリにはこのような標準的なエラー値が定義されています。
以下の例では、新しいパッケージを使用します。
05 package main
07 import (
08 "./file";
09 "fmt";
10 "os";
11 )
13 func main() {
14 hello := []byte{'h', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd', '\n'};
15 file.Stdout.Write(hello);
16 file, err := file.Open("/does/not/exist", 0, 0);
17 if file == nil {
18 fmt.Printf("can't open file; err=%s\n", err.String());
19 os.Exit(1);
20 }
21 }
import内の、./fileの./の部分は、コンパイラに対して、パッケージがインストールされているディレクトリからではなく、このパッケージ自身のディレクトリからインポートするように指示しています。
最後にプログラムを実行してみましょう。
% helloworld3
hello, world
can't open file; err=No such file or directory
%
Rotting cats¶
fileパッケージで作成した簡易版のUnixコマンドのcat(1)が progs/cat.go になります。
05 package main
07 import (
08 "./file";
09 "flag";
10 "fmt";
11 "os";
12 )
14 func cat(f *file.File) {
15 const NBUF = 512;
16 var buf [NBUF]byte;
17 for {
18 switch nr, er := f.Read(&buf); true {
19 case nr < 0:
20 fmt.Fprintf(os.Stderr, "cat: error reading from %s: %s\n", f.String(), er.String());
21 os.Exit(1);
22 case nr == 0: // EOF
23 return;
24 case nr > 0:
25 if nw, ew := file.Stdout.Write(buf[0:nr]); nw != nr {
26 fmt.Fprintf(os.Stderr, "cat: error writing from %s: %s\n", f.String(), ew.String());
27 }
28 }
29 }
30 }
32 func main() {
33 flag.Parse(); // 引数のリストを読み取り、フラグをセットする
34 if flag.NArg() == 0 {
35 cat(file.Stdin);
36 }
37 for i := 0; i < flag.NArg(); i++ {
38 f, err := file.Open(flag.Arg(i), 0, 0);
39 if f == nil {
40 fmt.Fprintf(os.Stderr, "cat: can't open %s: error %s\n", flag.Arg(i), err);
41 os.Exit(1);
42 }
43 cat(f);
44 f.Close();
45 }
46 }
ここまでは簡単なはずでした。しかし、switch文はいくつかの新しい機能を提供します。forループのようにifやswitchは初期化を行うことができます。18行目のswitch文はf.Read()からの戻り値を保持する変数nrとerを作るために初期化します。(25行目のifも同じ意図です)switch文は通常通り、値に合致する最初のケースを探しながら上から下にケースを評価します。ケース式は同じ型である限り、定数や整数でなくてもよいのです。
switch値は単なるtrueなのですが、抜けられるのでしょうか。for文と同じように、値がない場合はtrueを意味します。実際、このようなswitch文はif-else形式です。この間、各ケースは暗黙のbreakを持っていると言えます。
25行目で(それ自体がスライスなのですが)入力バッファをスライスしながらWrite()を呼びます。スライスはGoの標準的なI/Oバッファを扱う方法を提供します。
さて、入力値に対してROT13をオプションで行うcatの派生形を作成しましょう。バイトで処理するのは簡単ですが、代わりにGoのインタフェースの概念を利用します。
cat()サブルーチンはfのRead()とString()という2つのメソッドのみしか使用しません。そこで、これら2つのメソッドを持つインタフェースを定義することから始めてみましょう。これは progs/cat_rot13.go のコードです。
26 type reader interface {
27 Read(b []byte) (ret int, err os.Error);
28 String() string;
29 }
どの型もreaderの2つのメソッドを持つのか。他のメソッドが何であるかに関わらず、型はメソッドを持つのか。というのはインタフェースの実装と言われています。file.Fileはこれらのメソッドを実装しているので、readerインタフェースを実装しています。catサブルーチンを*file.Fileの代わりにreaderを受け付けるために微調整できます。そして、それはうまくいくでしょう。既存のreaderをラップし、データに対してrot13を行うreaderを実装する2番目の型を書いて、最初のものを少し装飾してみましょう。これを行うには、型を定義し、メソッドを実装するだけでよいのです。これがreaderインタフェースの2番目の実装です。
31 type rotate13 struct {
32 source reader;
33 }
35 func newRotate13(source reader) *rotate13 {
36 return &rotate13{source}
37 }
39 func (r13 *rotate13) Read(b []byte) (ret int, err os.Error) {
40 r, e := r13.source.Read(b);
41 for i := 0; i < r; i++ {
42 b[i] = rot13(b[i])
43 }
44 return r, e
45 }
47 func (r13 *rotate13) String() string {
48 return r13.source.String()
49 }
50 // rotate13の実装はここまで
(42行目で呼ばれているrot13関数にはあまり意味がなく、ここで再作成する必要ありません。)
新しい機能を使用するために、フラグを定義します。
14 var rot13Flag = flag.Bool("rot13", false, "rot13 the input")
そしてほとんど同じcat()関数内から使います。
52 func cat(r reader) {
53 const NBUF = 512;
54 var buf [NBUF]byte;
56 if *rot13Flag {
57 r = newRotate13(r)
58 }
59 for {
60 switch nr, er := r.Read(&buf); {
61 case nr < 0:
62 fmt.Fprintf(os.Stderr, "cat: error reading from %s: %s\n", r.String(), er.String());
63 os.Exit(1);
64 case nr == 0: // EOF
65 return;
66 case nr > 0:
67 nw, ew := file.Stdout.Write(buf[0:nr]);
68 if nw != nr {
69 fmt.Fprintf(os.Stderr, "cat: error writing from %s: %s\n", r.String(), ew.String());
70 }
71 }
72 }
73 }
(引数の型を変更することを除けば、mainでラップし、cat()サブルーチンをそのままにしておくことができます。エクササイズだと考えてください。)56-58行目で全てを設定しています。rot13フラグがtrueならば、受け取ったreaderをrotate13でラップし、処理を進めます。インタフェース変数は値であり、ポインタではないことに注意してください。つまり引数はreader型であり、*readerではありません。even though under the covers 構造体へのポインタを保持します。
それでは動作させてみます。
% echo abcdefghijklmnopqrstuvwxyz | ./cat
abcdefghijklmnopqrstuvwxyz
% echo abcdefghijklmnopqrstuvwxyz | ./cat --rot13
nopqrstuvwxyzabcdefghijklm
%
依存性注入の愛好者は、インタフェースがファイル記述子の実装を代替する容易さに喜ぶかもしれません。
Interfaces are a distinctive feature of Go. An interface is implemented by a type if the type implements all the methods declared in the interface. This means that a type may implement an arbitrary number of different interfaces. There is no type hierarchy; things can be much more ad hoc, as we saw with rot13. The type file.File implements reader; it could also implement a writer, or any other interface built from its methods that fits the current situation. Consider the empty interface
type Empty interface {}
すべての型がコンテナのように役に立つ空のインタフェースを実装します。
ソート¶
インターフェースはポリモルフィズムを簡単な形式で提供します。これはオブジェクトが行うことの定義といかにそれを行うかを分離し、同じインターフェース変数で時に応じて異なる実装を使わせることが可能となります。
例として、progs/sort.goから取ってきた簡単なソートアルゴリズムを見てみましょう。
13 func Sort(data Interface) {
14 for i := 1; i < data.Len(); i++ {
15 for j := i; j > 0 && data.Less(j, j-1); j-- {
16 data.Swap(j, j-1);
17 }
18 }
19 }
このコードは3つのメソッドを必要とします。これをソートのインターフェースにラップしてみましょう。
07 type Interface interface {
08 Len() int;
09 Less(i, j int) bool;
10 Swap(i, j int);
11 }
Len, Less, Swapを実装したものであれば、どんな型でもSortを適用することが可能です。ソートパッケージは整数、文字列などの配列をソートするために必要となるメソッドを含んでいます。次に整数の配列をソートするコードを見てみましょう。
33 type IntArray []int
35 func (p IntArray) Len() int { return len(p); }
36 func (p IntArray) Less(i, j int) bool { return p[i] < p[j]; }
37 func (p IntArray) Swap(i, j int) { p[i], p[j] = p[j], p[i]; }
ここではnon-struct型のためのメソッド定義を見てきました。パッケージに定義したどんな型のメソッドも定義することが可能です。
progs/sortmain.gから、ここまでのコードをテストするルーチンを見てみます。
12 func ints() {
13 data := []int{74, 59, 238, -784, 9845, 959, 905, 0, 0, 42, 7586, -5467984, 7586};
14 a := sort.IntArray(data);
15 sort.Sort(a);
16 if !sort.IsSorted(a) {
17 panic()
18 }
19 }
ある型をソートするためにしなければいけないことは次のように3つのメソッドを定義するだけです。
30 type day struct {
31 num int;
32 shortName string;
33 longName string;
34 }
36 type dayArray struct {
37 data []*day;
38 }
40 func (p *dayArray) Len() int { return len(p.data); }
41 func (p *dayArray) Less(i, j int) bool { return p.data[i].num < p.data[j].num; }
42 func (p *dayArray) Swap(i, j int) { p.data[i], p.data[j] = p.data[j], p.data[i]; }
Printing¶
これまでに挙げた出力フォーマットの例は、比較的単純なものでした。この章では、Goを用いてもう少し上手くI/Oを整形する方法を紹介します。
PrintfやFprintfなどが含まれるパッケージfmtについて簡単な使い方を見てきましたが、fmtパッケージにおいてPrintfは内部的に以下ように宣言されています:
Printf(format string, v ...) (n int, errno os.Error)
この3つのドット ... は可変長引数のリストを表しています。Cであればstdarg.hマクロを使って処理されるところですが、Goの場合は空のインターフェイス変数(interface {})を通して、リフレクションライブラリによって展開されます。少しオフトピック気味ですが、GoのPrintfが持つすばらしい特性について説明するのにリフレクションはうってつけです。Printfは自身の引数の型を動的に見つけ出す事ができるのです。
具体的には例えば 、Cでは各フォーマットがそれに対応する引数の型と完全に一致している必要があります。多くの場合Goはもっと簡単です。例えば%lludを指定する代わりに、%dとするだけでよいのです。Printfは整数型のサイズも符号の有無も知っており、あなたの代わりに常に正しい結果を導き出してくれるのです。スニペット:
10 var u64 uint64 = 1<<64-1;
11 fmt.Printf("%d %d\n", u64, int64(u64));
これは以下のように出力されます:
18446744073709551615 -1
それでも面倒なら、%vを使えばどのような値でも(配列や構造体でも)、分かりやすく適切なかたちで出力されます。
14 type T struct { a int; b string };
15 t := T{77, "Sunset Strip"};
16 a := []int{1, 2, 3, 4};
17 fmt.Printf("%v %v %v\n", u64, t, a);
これは以下のように出力されます:
18446744073709551615 {77 Sunset Strip} [1 2 3 4]
Printfの代わりにPrintやPrintlnを使えば、フォーマットは必要ありません。これらは自動的にフォーマット処理を行います。具体的には引数の要素に対し%vに相当する処理を行い、Printが結果をそのまま出力するのに対してPrintlnは各要素の間にスペースを追加し、末尾に改行を加えます。
18 fmt.Print(u64, " ", t, " ", a, "\n");
19 fmt.Println(u64, t, a);
もしあなたが独自の型をPrintfやPrintにフォーマットさせたければ、string型の返り値を持つString()メソッドを用意しておくだけでよいのです。printのルーティンはフォーマットする値にメソッドが実装されているかどうかを検査し、もしそうであれば他のどのフォーマット処理でもなくそのメソッドを使います。わかりやすい例を示します。
09 type testType struct { a int; b string }
11 func (t *testType) String() string {
12 return fmt.Sprint(t.a) + " " + t.b
13 }
15 func main() {
16 t := &testType{77, "Sunset Strip"};
17 fmt.Println(t)
18 }
*testType はString()メソッドを持っているので、その型のデフォルトフォーマッタはこのメソッドを使って出力を行うことになります。
77 Sunset Strip
String()メソッドがそのフォーマットを行う為にSprint(stringを返す明らかなGoの異形です)をコールしていることに注目してください。特別なフォーマッタはfmtライブラリを再帰的に使うことが出来ます。
Printfがもつその他の機能としては、対象の値の型を出力する%T指定子があります。これはポリモーフィックなコードをデバッグする際に重宝します。
フラグや精度を用いて完全なカスタムフォーマットを指定することも可能ですが、本題から少しそれるので、探求する余地を残しておくつもりです。
もっとも、あなたはString()が実装している型をPrintfがどうやって判断しているのかをを知りたいかもしれません。 実際には、対象となる値がメソッドを実装するインターフェイス変数に変換できるかどうかを調べています。概念的には、与えられた値vに対して以下のような処理がなされます:
type Stringer interface {
String() string
}
s, ok := v.(Stringer); // Test whether v implements "String()"
if ok {
result = s.String()
} else {
result = defaultOutput(v)
}
このコードはvに格納された値がStringerインターフェイスの要件を満たすかどうかをテストするために``type assertion’’ (v.(Stringer))を使っています。要件を満たす場合、sはメソッドを実装したインターフェイス変数となり、okはtrueとなります。(この”カンマ, ok”というパターンはGoにおけるイディオムのひとつで、型の変換・マップアップデート・コミュニケーション等によく使われますが、このチュートリアルではここでしか登場しません。)反対に要件が満たされない場合、okはfalseとなります。
このスニペットにおけるStringerという名前は、このようにシンプルなメソッドセットを表現するインターフェイスに”[e]r”を付加するという慣習に倣っています。
最後にもう一つ助言を。PrintfやSprintfの他にも、Fprintfなどがあります。但しCとは違い、第一引数はファイルではありません。代わりにio.Wirter型の変数をとります。それはioライブラリ内で定義されているインターフェイス型です:
type Writer interface {
Write(p []byte) (n int, err os.Error);
}
(このインターフェイスはもう一つの慣習的な命名規則を用いています。ここではWiteですが、他にもio.Readerやio.ReadWriter等があります。)この事によって、たとえそれがどんな型であっても標準的なWrite()メソッドを実装していさえすれば、ファイルのみにとどまらずネットワークチャンネルやバッファ等からFprintfをコールする事が出来ます。
素数の計算¶
それでは、並列プログラミングのプロセスとコミュニケーションの話しを始めたいと思います。この話題はとても大きな話題なので、ある程度、並列プログラミングについて知っているという仮定で手短に説明してきます。
古典的な素数計算のプログラムは、素数のふるいとして実装されます。計算上はここで説明するものよりも、エラトステネスのふるいの方が効率がいいのですが、ここではアルゴリズムよりも並列計算にフォーカスしています。これは、すべての自然数を含むストリームを受け取り、それぞれの素数ごとに、その倍数を排除していくフィルタが列状に連なっています。それぞれのステップでは、それまでに計算された素数のフィルタの列がある状態から始まり、そのフィルタを通り抜けた次の数が、次の素数ということになります。その素数によって、次のフィルタが作成されます。
以下の画像はフローを表した図になります。それぞれの箱はフィルタを表し、その前のフィルタから出てきた最初の数値を使って作られます。
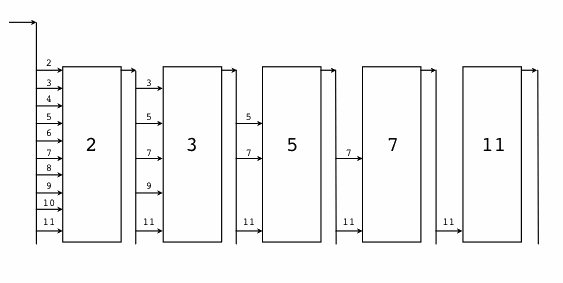
整数のストリームを作成するには、Goのチャンネルを使用します。これはCSP(Communicating Sequential Processes?)の子孫から借りてきた機能で、2つの並列計算プログラムをつなぐ、通信チャンネルとして表現されます。Goでは、チャンネル変数はコミュニケーションの面倒を見る実行時オブジェクトへの参照になっています。マップやスライスを使用するのと同じように、使用すると、新しいチャンネルを作成します。
以下のコードは、 progs/sieve.go の最初の関数です。
09 // チャンネル'ch'に対して、2, 3, 4, ... という数値の列を順番に送信します
10 func generate(ch chan int) {
11 for i := 2; ; i++ {
12 ch <- i // 'i'をチャンネル'ch'に送信
13 }
14 }
この生成関数は、 2, 3, 4, 5という数値の列を、引数で渡されたチャンネル’ch’に送信します。送信するときは、バイナリ通信演算子の <- を使用します。チャンネルの操作を行うとブロックします。そのため、もしも’ch’の値を受け取るコードがなければ、次にチャンネルが操作可能になるまで送信操作は待たされることになります。
Filter関数は3つの引数を持っています。入力のチャンネルと、出力のチャンネル、および素数になります。この関数は入力のチャンネルの値を受け取って、値のコピーを出力のチャンネルに送信しますが、渡された素数で割ることが可能な値が来た場合は途中で破棄します。単項の通信演算子の <- を使って、入力のチャンネルの次の値を受信します。
16 // 'in'チャンネルから値をコピーして、'out'チャンネルに送信します
17 // 'prime'で割ることが可能な数は削除します
18 func filter(in, out chan int, prime int) {
19 for {
20 i := <-in; // 'in'から値を受信して、'i'に格納
21 if i % prime != 0 {
22 out <- i // 'i'を'out'チャンネルに送信
23 }
24 }
25 }
ジェネレータとフィルターはそれぞれ並列に実行されます。Goはプロセス/スレッド/軽量プロセス/コルーチンにあたる固有の機能を持っています。表記上の混乱を避けるために、Goではこのような並列計算実行をGoroutineと呼んでいます。関数を呼び出してgoroutineを開始するためには、 go というキーワードを前につけて呼びます。こうすると、同じアドレス空間で並列に関数を実行することができます。
go sum(hugeArray); // バックグラウンドで合計を計算します
もしも計算が完了したのを知りたければ、チャンネルを渡して結果を返してもらうようにします:
ch := make(chan int);
go sum(hugeArray, ch);
// ... しばらくの間別のことをします
result := <-ch; // 並列で計算している関数の終了を待って、結果を受け取ります
それでは、サンプルの、素数のふるいの例に戻ります。ここでは、ふるいのパイプラインをつなぎ合わせています:
28 func main() {
29 ch := make(chan int); // 新しいチャンネルを作成します
30 go generate(ch); // goroutineとしてgenerate()を実行します
31 for {
32 prime := <-ch;
33 fmt.Println(prime);
34 ch1 := make(chan int);
35 go filter(ch, ch1, prime);
36 ch = ch1
37 }
38 }
29行目ではチャンネルを初期化してgenerate()関数に渡しています。generate()はチャンネルに値を入れ始めます。それぞれの素数はチャンネルから出力されます。出力されると、新しいフィルタがパイプラインに追加され、そのフィルタの出力チャンネルが、新しい’ch’の値になります。
ふるいのプログラムを変更して、このスタイルのプログラムの一般的なパターンを使用してみます。以下のプログラムはgenerate()関数の別バージョンです。これは progs/sieve1.go に格納されています:
10 func generate() chan int {
11 ch := make(chan int);
12 go func(){
13 for i := 2; ; i++ {
14 ch <- i
15 }
16 }();
17 return ch;
18 }
このバージョンはすべてのセットアップを内部で行っています。内部で出力チャンネルを作成し、関数リテラルをgoroutineとして実行しています。最後に、呼び出し元に、内部で作成したチャンネルを返しています。これは並列実行のためのファクトリ関数になっていて、goroutineを実行してコネクションを返すようになっています。
関数のリテラル表記(12行目-16行目)を使うと、無名関数を作ることができて、その場で実行することができます。ローカル変数の ch は関数リテラルの中でも使用することができ、generate()関数から抜けた後も使用することができます。
同じ変更をfilter()関数にも適用します:
21 func filter(in chan int, prime int) chan int {
22 out := make(chan int);
23 go func() {
24 for {
25 if i := <-in; i % prime != 0 {
26 out <- i
27 }
28 }
29 }();
30 return out;
31 }
sieve(ふるい)関数のメインループは、呼ばれる側の関数をファクトリに変更したために、こちらもシンプルでクリーンになりました:
33 func sieve() chan int {
34 out := make(chan int);
35 go func() {
36 ch := generate();
37 for {
38 prime := <-ch;
39 out <- prime;
40 ch = filter(ch, prime);
41 }
42 }();
43 return out;
44 }
素数のふるいを行うmainのインタフェースは、primesチャンネルになりました:
46 func main() {
47 primes := sieve();
48 for {
49 fmt.Println(<-primes);
50 }
51 }
多重化¶
channelを使うことによって複数の独立したgoroutineをmultiplexerを書くことなく処理することが出来ます。channelをメッセージに含めてサーバーに送信し、それを使って送信元に返事をします。現実的なクライアントサーバープログラムはコード量が多いので、ここでは簡略化したものを使って説明を行います。これはリクエスト型の定義から始まり、その中には返事するために使用するchannelが組込まれています。
09 type request struct {
10 a, b int;
11 replyc chan int;
12 }
サーバーは簡単なもので、整数のバイナリ操作を行います。ここで処理をしてリクエストに返事を返すコードを見ていきます。
14 type binOp func(a, b int) int
16 func run(op binOp, req *request) {
17 reply := op(req.a, req.b);
18 req.replyc <- reply;
19 }
18行目でbinOpを整数値を2つ取り、3つ目のものを返す関数として定義しています。
サーバールーチンは延々とループし続け、リクエストを受けとり、処理をブロックさせないようにgoroutineを開始して実際の処理をさせます。
21 func server(op binOp, service chan *request) {
22 for {
23 req := <-service;
24 go run(op, req); // don't wait for it
25 }
26 }
サーバーを見慣れた方法で組み立てます。サーバーを開始してそれに接続したchannelを返します。
28 func startServer(op binOp) chan *request {
29 req := make(chan *request);
30 go server(op, req);
31 return req;
32 }
次に簡単なテストです。これはサーバーをオペレーターを付加して開始し、Nリクエストを返事を待たずに送信します。すべてのリクエストの送信が終わった時点で結果のチェックを行います。
34 func main() {
35 adder := startServer(func(a, b int) int { return a + b });
36 const N = 100;
37 var reqs [N]request;
38 for i := 0; i < N; i++ {
39 req := &reqs[i];
40 req.a = i;
41 req.b = i + N;
42 req.replyc = make(chan int);
43 adder <- req;
44 }
45 for i := N-1; i >= 0; i-- { // doesn't matter what order
46 if <-reqs[i].replyc != N + 2*i {
47 fmt.Println("fail at", i);
48 }
49 }
50 fmt.Println("done");
51 }
このプログラムの厄介なところはサーバーがきれいにシャットダウンされないことです。mainが返る時にいくつかのgoroutineが通信中のままブロックされて残ってしまいます。これを解決するためにquit channelをサーバーに渡します。
32 func startServer(op binOp) (service chan *request, quit chan bool) {
33 service = make(chan *request);
34 quit = make(chan bool);
35 go server(op, service, quit);
36 return service, quit;
37 }
quit channelをサーバー関数に渡し、サーバーはそれを次のようにして使います。
21 func server(op binOp, service chan *request, quit chan bool) {
22 for {
23 select {
24 case req := <-service:
25 go run(op, req); // don't wait for it
26 case <-quit:
27 return;
28 }
29 }
30 }
サーバー内でselect文はcaseで並んでいる複数の通信のうち開始出来るものを選択します。もしすべてブロックされていれば、そのうちの1つが開始出来る状態になるまで待ちます。複数のものが開始出来る状態となれば、ランダムでそのうちの1つが選択されます。この例では、selectを使うことでquitメッセージを受けとるまでサーバーにリクエストを待たせ、受け取った時点で実行を終了させることが出来ます。
あとはmainの終わりにあるquit channelをstrobeするだけです。
40 adder, quit := startServer(func(a, b int) int { return a + b });
...
55 quit <- true;
Goプログラミングや一般的な並列処理プログラミングはこれだけではありませんが、基礎的なところはは理解いただけたでしょう。
Except as noted, this content is licensed under Creative Commons Attribution 3.0.